This tutorial shows how to use Tensorflow to create a neural network that mimics 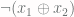 function. This function, abbreviated as XNOR, returns 1 only if
function. This function, abbreviated as XNOR, returns 1 only if 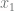 is equal to
is equal to 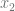 . The values are summarized in the table below:
. The values are summarized in the table below:

Andrew Ng shows in Lecture 8.5: Neural Networks – Representation how to construct a single neuron that can emulate a logical AND operation. The neuron is considered to act like a logical AND if it outputs a value close to 0 for (0, 0), (0, 1), and (1, 0) inputs, and a value close to 1 for (1, 1). This can be achieved as follows:
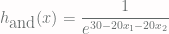
To recreate the above in tensorflow we first create a function that takes theta, a vector of coefficients, together with x1 and x2. We use the vector to create three constants, represented by tf.constant. The first one is the bias unit. The next two are used to multiply x1 and x2, respectively. The expression is then fed into a sigmoid function, implemented by tf.nn.sigmoid.
Outside of the function we create two placeholders. For Tensorflow a tf.placeholder is an operation that is fed data. These are going to be our x1 and x2 variables. Next we create a h_and operation by calling the MakeModel function with the coefficient vector as suggested by Andrew Ng.
def MakeModel(theta, x1, x2):
h = tf.constant(theta[0]) + \
tf.constant(theta[1]) * x1 + tf.constant(theta[2]) * x2
return tf.nn.sigmoid(h)
x1 = tf.placeholder(tf.float32, name="x1")
x2 = tf.placeholder(tf.float32, name="x2")
h_and = MakeModel([-30.0, 20.0, 20.0], x1, x2)
We can then print the values to verify that our model works correctly. When creating Tensorflow operations, we do not create an actual program. Instead, we create a description of the program. To execute it, we need to create a session to run it:
with tf.Session() as sess:
print " x1 | x2 | g"
print "----+----+-----"
for x in range(4):
x1_in, x2_in = x & 1, x > 1
print " %2.0f | %2.0f | %3.1f" % (
x1_in, x2_in, sess.run(h_and, {x1: x1_in, x2: x2_in}))
The above code produces the following output, confirming that we have correctly coded the AND function:
x1| x2 | g
----+----+-----
0 | 0 | 0.0
0 | 1 | 0.0
1 | 0 | 0.0
1 | 1 | 1.0
To get a better understanding of how a neuron, or more precisely, a sigmoid function with a linear input, emulates a logical AND, let us plot its values. Rather than just using four points, we compute its values for a set of 20 x 20 points from the range [0, 1]. First, we define a function that, for a given input function (a tensor) and a linear space, computes values of returned by the function (a tensor) when fed points from the linear space.
def ComputeVals(h, span):
vals = []
with tf.Session() as sess:
for x1_in in span:
vals.append([
sess.run(h, feed_dict={
x1: x1_in, x2: x2_in}) for x2_in in span
])
return vals
This is a rather inefficient way of doing this. However, at this stage we aim for clarity not efficiency. To plot values computed by the h_and tensor we use matplotlib. The result can be seen in Fig 1. We use coolwarm color map, with blue representing 0 and red representing 1.

Fig 1. Values of a neuron emulating the AND gate
Having created a logical AND, let us apply the same approach, and create a logical OR. Following Andrew Ng’s lecture, the bias is set to -10.0, while we use 20.0 as weights associated with x1 and x2. This has the effect of generating an input larger than or equal 10.0, if either x1 or x2 are 1, and -10, if both are zero. We reuse the same MakeModel function. We pass the same x1 and x2 as input, but change vector theta to [-10.0, 20.0, 20.0]
h_or = MakeModel([-10.0, 20.0, 20.0], x1, x2)
or_vals = ComputeVals(h_or, span)
When plotted with matplotlib we see the graph shown in Fig 2.

Fig 2. Values of a neuron emulating the OR gate
The negation can be crated by putting a large negative weight in front of the variable. Andrew Ng’s chose  . This way
. This way 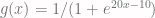 returns
returns  for
for 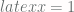 and
and 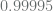 for
for  . By using −20 with both
. By using −20 with both x1 and x2 we get a neuron that produces a logical and of negation of both variables, also known as the NOR gate:  .
.
h_nor = MakeModel([10.0, -20.0, -20.0], x1, x2)
nor_vals = ComputeVals(h_nor, span)
The plot of values of our h_nor function can be seen in Fig 3.
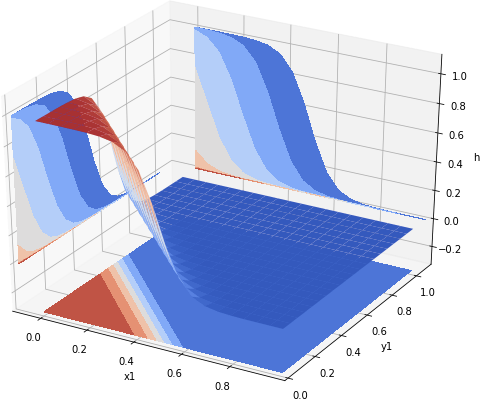
Fig 3. Value of a neuron emulating the NOR gate
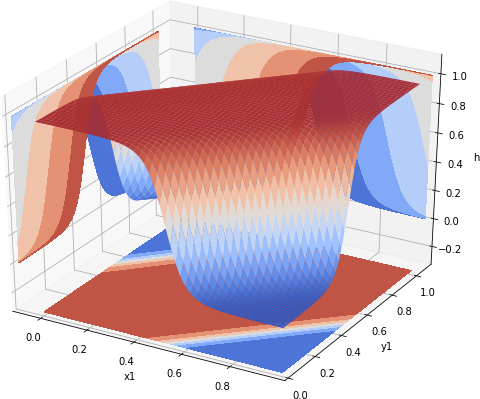
With the last gate, we have everything in place. The first neuron generates values close to one when both x1 and x2 are 1, the third neuron generates value close to one when x1 and x2 are close to 0. Finally, the second neuron can perform a logical OR of values generated from two neurons. Thus our xnor neuron can be constructed by passing h_and and h_nor as inputs to h_or neuron. In Tensorflow this simply means that rather than passing x1 and x2 placeholders, when constructing h_or function, we pass h_and and h_nor tensors:
h_xnor = MakeModel([-10.0, 20.0, 20.0], h_nor, h_and)
xnor_vals = ComputeVals(h_xnor, span)
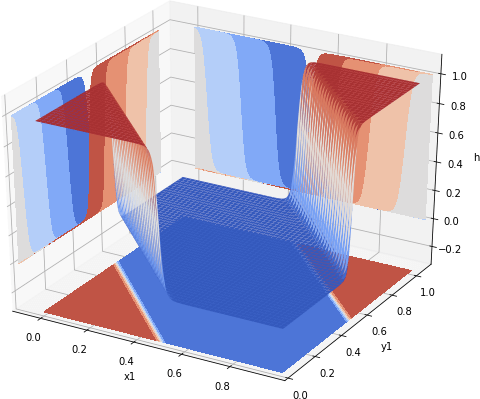
Again, to see what is happening, let us plot the values of h_xnor over the [0, 1] range. These are shown in Fig 4.

Fig 4. Value of a neural net emulating XNOR gate
In a typical Tensorflow application we would not see only constants being used to create a model. Instead constants are used to initialize variables. The reason we could use only constants is that we do not intend to train the model. Instead we already knew, thanks to Andrew Ng, the final values of all weights and biases.
Finally, the solution that we gave is quite inefficient. We will show next how by vectorising it one can speed it up by a factor of over 200 times. This is not an insignificant number, considering how simple our model is. In larger models vectorization can give us even more dramatic improvements.
Resources
You can download the Jupyter notebook from which code snippets were presented above from github xnor-basic repository.




 . Next, we compute
. Next, we compute  , where
, where  is a 25 by 10 matrix and
is a 25 by 10 matrix and  is a vector of size 10.
is a vector of size 10.![\left[ \begin{array}{ccccccc} 1 & 1 & 1 & \cdots & 1 & 1 & 1 \\ 0 & 0 & 0 & \cdots & 0 & 0 & 1 \\ 1 & 1 & 1 & \cdots & 1 & 1 & 1 \\ & & & \ddots & & & \\ 1 & 1 & 1 & \cdots & 1 & 1 & 1 \\ 1 & 1 & 1 & \cdots & 0 & 0 & 1 \end{array} \right] \times \left[ \begin{array}{cccc} w_{0,0} & w_{0,1} & \cdots & w_{0,9} \\ w_{1,0} & w_{1,1} & \cdots & w_{1,9} \\ w_{2,0} & w_{2,1} & \cdots & w_{2,9} \\ & & \ddots & \\ w_{23,0} & w_{23,1} & \cdots & w_{23,9} \\ w_{24,0} & w_{24,1} & \cdots & w_{24,9} \end{array} \right] + \left[ \begin{array}{c} b_0 \\ b_1 \\ \vdots \\ b_9 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccccccc%7D+1+%26+1+%26+1+%26+%5Ccdots+%26+1+%26+1+%26+1+%5C%5C+0+%26+0+%26+0+%26+%5Ccdots+%26+0+%26+0+%26+1+%5C%5C+1+%26+1+%26+1+%26+%5Ccdots+%26+1+%26+1+%26+1+%5C%5C+%26+%26+%26+%5Cddots+%26+%26+%26+%5C%5C+1+%26+1+%26+1+%26+%5Ccdots+%26+1+%26+1+%26+1+%5C%5C+1+%26+1+%26+1+%26+%5Ccdots+%26+0+%26+0+%26+1+%5Cend%7Barray%7D+%5Cright%5D+%5Ctimes+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcccc%7D+w_%7B0%2C0%7D+%26+w_%7B0%2C1%7D+%26+%5Ccdots+%26+w_%7B0%2C9%7D+%5C%5C+w_%7B1%2C0%7D+%26+w_%7B1%2C1%7D+%26+%5Ccdots+%26+w_%7B1%2C9%7D+%5C%5C+w_%7B2%2C0%7D+%26+w_%7B2%2C1%7D+%26+%5Ccdots+%26+w_%7B2%2C9%7D+%5C%5C+%26+%26+%5Cddots+%26+%5C%5C+w_%7B23%2C0%7D+%26+w_%7B23%2C1%7D+%26+%5Ccdots+%26+w_%7B23%2C9%7D+%5C%5C+w_%7B24%2C0%7D+%26+w_%7B24%2C1%7D+%26+%5Ccdots+%26+w_%7B24%2C9%7D+%5Cend%7Barray%7D+%5Cright%5D+%2B+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+b_0+%5C%5C+b_1+%5C%5C+%5Cvdots+%5C%5C+b_9+%5Cend%7Barray%7D+%5Cright%5D+&bg=fffdfd&fg=606666&s=0&c=20201002)
 referred to as logits.
referred to as logits.  is proportional to the likelihood that the row represents digit
is proportional to the likelihood that the row represents digit  . When training a model, we use gradient descent to nudge the model so that if a row represents, say, a 0, then
. When training a model, we use gradient descent to nudge the model so that if a row represents, say, a 0, then  is greater than
is greater than  …
…  .
.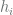 is expressed as
is expressed as
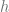 is as close as possible to
is as close as possible to ![[1, 0, 0, 0, 0, 0, 0, 0, 0, 0]](https://s0.wp.com/latex.php?latex=%5B1%2C+0%2C+0%2C+0%2C+0%2C+0%2C+0%2C+0%2C+0%2C+0%5D&bg=fffdfd&fg=606666&s=0&c=20201002) . This requirement is captured with the help of cross entropy function:
. This requirement is captured with the help of cross entropy function:
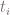 is the true (desired) value, taking either 1 or 0. Let us express the above using Tensorflow:
is the true (desired) value, taking either 1 or 0. Let us express the above using Tensorflow: ,
, 




 features
features 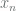 are extended by adding feature
are extended by adding feature 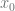 which is always set to 1. This way the hypothesis can be expressed as:
which is always set to 1. This way the hypothesis can be expressed as:
 examples, the task of linear regression can be expressed as a task of finding vector
examples, the task of linear regression can be expressed as a task of finding vector  such that
such that![\left[ \begin{array}{cccc} \theta_0 & \theta_1 & \cdots & \theta_n \end{array} \right] \times \left[ \begin{array}{ccccc} 1 & 1 & \cdots & 1 \\ x^{(1)}_1 & x^{(2)}_1 & \cdots & x^{(m)}_1 \\ & & \vdots \\ x^{(n)}_m & x^{(n)}_m & \cdots & x^{(n)}_m \\ \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcccc%7D+%5Ctheta_0+%26+%5Ctheta_1+%26+%5Ccdots+%26+%5Ctheta_n+%5Cend%7Barray%7D+%5Cright%5D+%5Ctimes+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccccc%7D+1+%26+1+%26+%5Ccdots+%26+1+%5C%5C+x%5E%7B%281%29%7D_1+%26+x%5E%7B%282%29%7D_1+%26+%5Ccdots+%26+x%5E%7B%28m%29%7D_1+%5C%5C+%26+%26+%5Cvdots+%5C%5C+x%5E%7B%28n%29%7D_m+%26+x%5E%7B%28n%29%7D_m+%26+%5Ccdots+%26+x%5E%7B%28n%29%7D_m+%5C%5C+%5Cend%7Barray%7D+%5Cright%5D+&bg=fffdfd&fg=606666&s=0&c=20201002)
 . The “as close as possible” typically means that the mean sum of square errors between
. The “as close as possible” typically means that the mean sum of square errors between 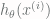 and
and  for
for ![i \in [1, m]](https://s0.wp.com/latex.php?latex=i+%5Cin+%5B1%2C+m%5D&bg=fffdfd&fg=606666&s=0&c=20201002) is minimized. This quantity is often referred to as cost or loss function:
is minimized. This quantity is often referred to as cost or loss function:
 . Instead, we use a tensor of size 0 (also known as scalar), called
. Instead, we use a tensor of size 0 (also known as scalar), called 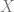 , in such a way that the i-th row is the i-th sample. Our formulation thus has the form
, in such a way that the i-th row is the i-th sample. Our formulation thus has the form![h_{w,b}(X) = \left[ \begin{array}{ccc} \text{---} & (x^{(1)})^T & \text{---} \\ \text{---} & (x^{(2)})^T & \text{---} \\ & \vdots & \\ \text{---} & (x^{(m)})^T & \text{---} \end{array} \right] \times \left[ \begin{array}{c} w_1 \\ w_2 \\ \vdots \\ w_m \end{array} \right] + b](https://s0.wp.com/latex.php?latex=h_%7Bw%2Cb%7D%28X%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+%5Ctext%7B---%7D+%26+%28x%5E%7B%281%29%7D%29%5ET+%26+%5Ctext%7B---%7D+%5C%5C+%5Ctext%7B---%7D+%26+%28x%5E%7B%282%29%7D%29%5ET+%26+%5Ctext%7B---%7D+%5C%5C+%26+%5Cvdots+%26+%5C%5C+%5Ctext%7B---%7D+%26+%28x%5E%7B%28m%29%7D%29%5ET+%26+%5Ctext%7B---%7D+%5Cend%7Barray%7D+%5Cright%5D+%5Ctimes+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+w_1+%5C%5C+w_2+%5C%5C+%5Cvdots+%5C%5C+w_m+%5Cend%7Barray%7D+%5Cright%5D+%2B+b+&bg=fffdfd&fg=606666&s=0&c=20201002)
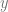 represented by placeholders. We would always create variables representing weights and biases, etc., and so on. By using
represented by placeholders. We would always create variables representing weights and biases, etc., and so on. By using 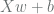 . In real applications this function can be arbitrarily complex. It could, for example, read data and labels from files, returning a fixed number of rows at a time.
. In real applications this function can be arbitrarily complex. It could, for example, read data and labels from files, returning a fixed number of rows at a time.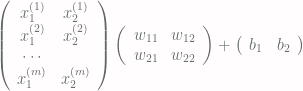
 input to a layer of neurons. Using
input to a layer of neurons. Using  instead
instead 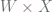 allows us to specify
allows us to specify 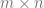 matrix. This is often easier than representing inputs as
matrix. This is often easier than representing inputs as  Fig 1. Data flow graph as rendered by tensorboard
Fig 1. Data flow graph as rendered by tensorboard