In the previous post we have showed how to encode XNOR function using a two layers deep neural net. The first layer consists of the NOR and AND gates. The second layer is a single OR gate. The Tensorflow implementation we developed is rather inefficient. This is due to the fact that all computations are done on individual variables. A better way is to create the model so that each layer of the neural net can be computed for a batch of inputs as matrix operations. The input to the first sigmoid function can be computed as follows:
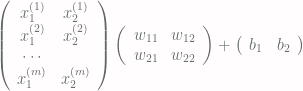
This leads to the following model:
X = tf.placeholder(tf.float32, [None, 2], name="X") W1 = tf.constant([[20.0, -20.0], [20.0, -20.0]]) b1 = tf.constant([-30, 10]) and_nor = tf.sigmoid(tf.add(tf.matmul(X, W1), b1)) W2 = tf.constant([[20.0], [20.0]]) b2 = tf.constant([-10.0]) h_xnor_fast = tf.sigmoid(tf.add(tf.matmul(and_nor, W2),b2))
X representing x1 and x2, has unrestricted first dimension. This allows us to specify arbitrary many inputs. The first layer also computes both AND and NOR gates in a single computation. The second layer takes a single input, the previous layer, and again computes the output in two matrix operation. The function that computes values also undergoes changes
def ComputeValsFast(h, span):
x1, x2 = np.meshgrid(span, span)
X_in = np.column_stack([x1.flatten(), x2.flatten()])
with tf.Session() as sess:
return np.reshape(sess.run(h, feed_dict={X: X_in}), x1.shape)
It takes the vector that defines a space of input values, flattens it and stacks it as two columns. Then all values can be computed as a single call to sess.run(), followed by the reshaping operation. The difference? The original operation on a MacBook Air run in about 3.07s per loop. The reformulated, so-called fast version, runs in 14.5ms per loop. This level of speed allows us to recompute values of the optimized xor for 10,000, rather than the original 400 points leading to the image shown in Fig 1.
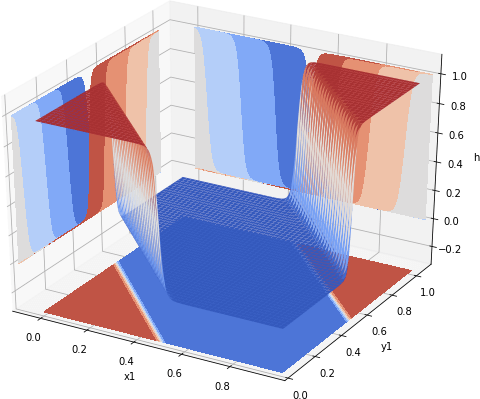
Fig 1. 100 x 100 XNOR values computed by a neural net.
Resources
You can download the Jupyter notebook from which code snippets were presented above from github xnor-fast repository.
