The first task is to train a model so that it can recognize 5 x 5 LCD digits, shown in Fig 1.

Fig 1. Images of ten LCD digits
To do this we use a linear regression, which is sufficiently powerful for a task of this complexity.
Each digit is represented as a 5 x 5 array of 0s and 1s. We flatten each one of the arrays into a vector of 25 floats. We stack all vectors forming a 2D array 



![\left[ \begin{array}{ccccccc} 1 & 1 & 1 & \cdots & 1 & 1 & 1 \\ 0 & 0 & 0 & \cdots & 0 & 0 & 1 \\ 1 & 1 & 1 & \cdots & 1 & 1 & 1 \\ & & & \ddots & & & \\ 1 & 1 & 1 & \cdots & 1 & 1 & 1 \\ 1 & 1 & 1 & \cdots & 0 & 0 & 1 \end{array} \right] \times \left[ \begin{array}{cccc} w_{0,0} & w_{0,1} & \cdots & w_{0,9} \\ w_{1,0} & w_{1,1} & \cdots & w_{1,9} \\ w_{2,0} & w_{2,1} & \cdots & w_{2,9} \\ & & \ddots & \\ w_{23,0} & w_{23,1} & \cdots & w_{23,9} \\ w_{24,0} & w_{24,1} & \cdots & w_{24,9} \end{array} \right] + \left[ \begin{array}{c} b_0 \\ b_1 \\ \vdots \\ b_9 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccccccc%7D+1+%26+1+%26+1+%26+%5Ccdots+%26+1+%26+1+%26+1+%5C%5C+0+%26+0+%26+0+%26+%5Ccdots+%26+0+%26+0+%26+1+%5C%5C+1+%26+1+%26+1+%26+%5Ccdots+%26+1+%26+1+%26+1+%5C%5C+%26+%26+%26+%5Cddots+%26+%26+%26+%5C%5C+1+%26+1+%26+1+%26+%5Ccdots+%26+1+%26+1+%26+1+%5C%5C+1+%26+1+%26+1+%26+%5Ccdots+%26+0+%26+0+%26+1+%5Cend%7Barray%7D+%5Cright%5D+%5Ctimes+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcccc%7D+w_%7B0%2C0%7D+%26+w_%7B0%2C1%7D+%26+%5Ccdots+%26+w_%7B0%2C9%7D+%5C%5C+w_%7B1%2C0%7D+%26+w_%7B1%2C1%7D+%26+%5Ccdots+%26+w_%7B1%2C9%7D+%5C%5C+w_%7B2%2C0%7D+%26+w_%7B2%2C1%7D+%26+%5Ccdots+%26+w_%7B2%2C9%7D+%5C%5C+%26+%26+%5Cddots+%26+%5C%5C+w_%7B23%2C0%7D+%26+w_%7B23%2C1%7D+%26+%5Ccdots+%26+w_%7B23%2C9%7D+%5C%5C+w_%7B24%2C0%7D+%26+w_%7B24%2C1%7D+%26+%5Ccdots+%26+w_%7B24%2C9%7D+%5Cend%7Barray%7D+%5Cright%5D+%2B+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+b_0+%5C%5C+b_1+%5C%5C+%5Cvdots+%5C%5C+b_9+%5Cend%7Barray%7D+%5Cright%5D+&bg=fffdfd&fg=606666&s=0&c=20201002)
The above expression gives us, for each row of 

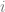
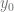

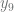
We cannot treat 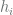

Using softmax converts values y to probabilities h. The goal of training a model is to make sure that when we see an image for, say, 0, the resulting vector 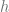
![[1, 0, 0, 0, 0, 0, 0, 0, 0, 0]](https://s0.wp.com/latex.php?latex=%5B1%2C+0%2C+0%2C+0%2C+0%2C+0%2C+0%2C+0%2C+0%2C+0%5D&bg=fffdfd&fg=606666&s=0&c=20201002)

Where 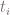
img_size = 5
shape_size = 5
kind_count = 10
learning_rate = 0.03
pixel_count = img_size * img_size
x = tf.placeholder(tf.float32,
shape=[None, img_size, img_size])
x_flat = tf.reshape(x, [-1, pixel_count])
y_true = tf.placeholder(tf.float32,
shape=[None, kind_count])
W = tf.Variable(tf.zeros([pixel_count, kind_count]))
b = tf.Variable(tf.zeros([kind_count]))
y_pred = tf.matmul(x_flat, W) + b
loss_op = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(
labels=y_true, logits=y_pred))
optimizer = tf.train.GradientDescentOptimizer(
learning_rate)
train_op = optimizer.minimize(loss_op)
correct_prediction = tf.equal(tf.argmax(y_pred, 1),
tf.argmax(y_true, 1))
accuracy_op = tf.reduce_mean(
tf.cast(correct_prediction, tf.float32))
First we set up a few parameters. Initially image size and shape size are going to be the same. This means that the shape completely fills the image. We set the number of kinds of images to 10, so that all ten digits are present. The learning rate defines how fast we follow the slope of the loss function. In our case we chose a conservative 0.03. Choosing a larger value can lead to a faster convergence, but it can also cause us to overshoot the minimum, once we are near it. Lines 7, 8 and 9 create placeholders for input data. Both x and y_true are going to be repeatedly fed batches of images and correct labels for those images. In line 12 we set up the weight matrix. In order to compute 
W must have pixel_count = 25 rows. It has 10 columns (or kind_count) to produce a vector of size 10. The i-th element of that vector is proportional to the likelihood that the given image represents digit i. Line 15 sets up the loss function. It is set as the mean value of softmax expression computed by taking predictions and true labels. Line 18 uses a gradient descent optimizer and line 20 uses it to create a training operation that minimizes the loss function by descending along the gradient of the mean value of the softmax expression. Line 21 computes, for each batch, how many predictions for that batch were correct. Finally, in line 23 we express accuracy as the sum of the correct predictions divided by the total number of predictions. Next comes the training of the model:
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
batch_maker = BatchMaker(img_data, true_kind, batch_size)
step_nbr = 0
while step_nbr < 5:
img_batch, label_batch = batch_maker.next()
train_op.run(feed_dict={x: img_batch, y_true: label_batch})
step_nbr += 1
We first train the model for five steps. After five steps we print a selection of images. As LCD digits are very regular and fit exactly inside each image, just 5 steps is sufficient to get 60% accuracy:

Fig 2. Predictions made by the model after five steps.
The model cannot distinguish between 1, 4, 7 and 9 and between 2 and 3. We continue training until accuracy is 1.
The final matrix W is shown in Fig 3. To better visualize W, we reshape each column of W into a 5 x 5 matrix. Then we normalize each value between -1 and 1. Finally, we plot 1 as red, -1 as blue, 0 as white, and intermediate values as shades of blue or red.

Fig 3. Matrix W at 100% accuracy.
The red color indicates positive interaction between the matrix and the image, while blue colors indicate negative interaction. Looking at 0, we can see that the model learned to distinguish between 0 and 8 by using negative weights for the line in the middle. For 1, the matrix strongly selects for a vertical line on the left, penalizing at the same time parts that would make the image look like 4, 7 or 9. 3 has positive interaction with almost all but 2 pixels, which would turn 3 into 8. The model did not learn the cleanest features, but it learned enough to tell each digit apart.
Clearly, linear regression can learn a number of features, given a well behaved problem. In the following posts we are going to show how a small change in the problem’s complexity causes linear regression to struggle. The change is to increase the image size, while keeping the digits sizes at 5. Deep neural networks are able to cope with this situation, at the expense of much longer training and much larger models. The final solution, that uses a convolutional neural network, can achieve fast training, 100% accuracy and small model size.
Resources
A Jupyter Notebook with the above code can be found at GitHub’s LCD repository.
 features
features 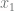 …
… 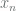 are extended by adding feature
are extended by adding feature 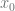 which is always set to 1. This way the hypothesis can be expressed as:
which is always set to 1. This way the hypothesis can be expressed as:
 examples, the task of linear regression can be expressed as a task of finding vector
examples, the task of linear regression can be expressed as a task of finding vector  such that
such that![\left[ \begin{array}{cccc} \theta_0 & \theta_1 & \cdots & \theta_n \end{array} \right] \times \left[ \begin{array}{ccccc} 1 & 1 & \cdots & 1 \\ x^{(1)}_1 & x^{(2)}_1 & \cdots & x^{(m)}_1 \\ & & \vdots \\ x^{(n)}_m & x^{(n)}_m & \cdots & x^{(n)}_m \\ \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcccc%7D+%5Ctheta_0+%26+%5Ctheta_1+%26+%5Ccdots+%26+%5Ctheta_n+%5Cend%7Barray%7D+%5Cright%5D+%5Ctimes+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccccc%7D+1+%26+1+%26+%5Ccdots+%26+1+%5C%5C+x%5E%7B%281%29%7D_1+%26+x%5E%7B%282%29%7D_1+%26+%5Ccdots+%26+x%5E%7B%28m%29%7D_1+%5C%5C+%26+%26+%5Cvdots+%5C%5C+x%5E%7B%28n%29%7D_m+%26+x%5E%7B%28n%29%7D_m+%26+%5Ccdots+%26+x%5E%7B%28n%29%7D_m+%5C%5C+%5Cend%7Barray%7D+%5Cright%5D+&bg=fffdfd&fg=606666&s=0&c=20201002)
 . The “as close as possible” typically means that the mean sum of square errors between
. The “as close as possible” typically means that the mean sum of square errors between 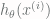 and
and  for
for ![i \in [1, m]](https://s0.wp.com/latex.php?latex=i+%5Cin+%5B1%2C+m%5D&bg=fffdfd&fg=606666&s=0&c=20201002) is minimized. This quantity is often referred to as cost or loss function:
is minimized. This quantity is often referred to as cost or loss function:
 . Instead, we use a tensor of size 0 (also known as scalar), called
. Instead, we use a tensor of size 0 (also known as scalar), called  , in such a way that the i-th row is the i-th sample. Our formulation thus has the form
, in such a way that the i-th row is the i-th sample. Our formulation thus has the form![h_{w,b}(X) = \left[ \begin{array}{ccc} \text{---} & (x^{(1)})^T & \text{---} \\ \text{---} & (x^{(2)})^T & \text{---} \\ & \vdots & \\ \text{---} & (x^{(m)})^T & \text{---} \end{array} \right] \times \left[ \begin{array}{c} w_1 \\ w_2 \\ \vdots \\ w_m \end{array} \right] + b](https://s0.wp.com/latex.php?latex=h_%7Bw%2Cb%7D%28X%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccc%7D+%5Ctext%7B---%7D+%26+%28x%5E%7B%281%29%7D%29%5ET+%26+%5Ctext%7B---%7D+%5C%5C+%5Ctext%7B---%7D+%26+%28x%5E%7B%282%29%7D%29%5ET+%26+%5Ctext%7B---%7D+%5C%5C+%26+%5Cvdots+%26+%5C%5C+%5Ctext%7B---%7D+%26+%28x%5E%7B%28m%29%7D%29%5ET+%26+%5Ctext%7B---%7D+%5Cend%7Barray%7D+%5Cright%5D+%5Ctimes+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+w_1+%5C%5C+w_2+%5C%5C+%5Cvdots+%5C%5C+w_m+%5Cend%7Barray%7D+%5Cright%5D+%2B+b+&bg=fffdfd&fg=606666&s=0&c=20201002)
 represented by placeholders. We would always create variables representing weights and biases, etc., and so on. By using
represented by placeholders. We would always create variables representing weights and biases, etc., and so on. By using 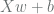 . In real applications this function can be arbitrarily complex. It could, for example, read data and labels from files, returning a fixed number of rows at a time.
. In real applications this function can be arbitrarily complex. It could, for example, read data and labels from files, returning a fixed number of rows at a time.