In version 1.0 of Tensorflow released in Feb 2017 a higher level APIs, called layers, were added. These allow a reduction in the amount of boilerplate code one has to write. For example, for linear regression with 
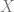
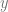
x_feature = tf.contrib.layers.real_valued_column('X', 4)
regressor = tf.contrib.learn.LinearRegressor(
[x_feature],
optimizer=tf.train.GradientDescentOptimizer(0.3))
regressor.fit(
input_fn=create_training_fn(m_examples, w_true, b_true),
steps=500)
eval_dict = regressor.evaluate(
input_fn=create_training_fn(10, w_true, b_true), steps=1)
First we describe our features. In our simple case we create a real valued feature, named X, 4 columns wide. We could have created four features x1 … x4. However, this would make input function more complex. Next, we create a linear regressor. We pass feature columns to it. It must be an iterable. Otherwise it will fail with fairly mysterious errors. The second parameter is the optimizer. We chose to rely on the same gradient descent optimizer as in the last example. Having created the regressor we train it, by calling fit method. This is done with the help of the input function that feeds labeled data into it. We run it for 500 steps. Finally, we evaluate how well the regressor fits the data. In real application, the last step should be called with data not included in the training set.
The input function must return a pair. The first element of the pair must be a map from feature names to feature values. The second element must be the target values (i.e., labels) that the regressor is learning. In our case the function is fairly simple, as shown below:
def create_training_fn(m, w, b):
def training_fn_():
X = np.random.rand(m, w.shape[0])
return ({'X': tf.constant(X)},
tf.constant(np.matmul(X, w) + b))
return training_fn_
It generates a random set of input data, X, and computes the target value as 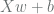
Last, let us see how well the LinearRegressor did. Typically, one has just the loss function as the guide. However, for us, we also know w and b. Thus we can compare them with what the regressor computed, by fetching regressor’s variables:
print "loss", eval_dict['loss']
print "w true ", w_true.T[0]
print "w found", regressor.get_variable_value('linear/X/weight').T[0]
print "b true %.4f" % b_true[0]
print "b found", regressor.get_variable_value('linear/bias_weight')[0]
loss 8.81575e-06
w true [ 1.7396 62.2283 59.7082 6.9788]
w found [ 1.7304 62.2178 59.6973 6.9751]
b true -4.7938
b found -4.77659
Both the weights and the bias are very close to the one we used to train the regressor.
It is worth mentioning that regressors also offer a way of tracking internal state that can be used to analyze their behavior using TensorBoard. There are also methods that allow regressor’s state to be saved and later restored. Finally, the predict function can be used to compute regressor output, for any unlabeled input.
