Convolutional neural networks, or CNNs, found applications in computer vision and audio processing. More generally they are suitable for tasks that use a number of features to identify interesting objects, events, sound, etc. The power of CNNs comes from the fact that they can be trained to come up with features that are hard to define by hand. What are “features”, you may ask? It is probably easier to understand this concept through example. Suppose your task is to write a program that can analyze an image of an LCD display and can recognize if the display shows 0 or 1. Thus your program is presented with images that look as follows:


Fig 1. Images representing 0 and 1 on an LCD display
A possible solution would be to convert images to a numeric representation. If 0 was used to represent black pixels, and 1 to represent white pixels, the above images would have numeric representation as shown below:
[[ 1 1 1 1 1] [[ 0 0 0 0 1] [ 1 0 0 0 1] [ 0 0 0 0 1] [ 1 0 0 0 1] [ 0 0 0 0 1] [ 1 0 0 0 1] [ 0 0 0 0 1] [ 1 1 1 1 1]] [ 0 0 0 0 1]]
Fig 2. Numeric representation of images of 0 and 1
One could make a vertical line a feature (x[i][j] == 1, i = 0 .. 5). Then all the program would have to do is to count the number of features found in each image. If it found two, it would declare that it sees a 0, if it found one, it would output 1. Of course as features go, this one is somewhat weak, as adding 8 to the set of displayed numbers would make the program incorrectly identify it as 0. The point is not, however, to come up with a set of fool-proof features, but rather to illustrate what a feature is.
Back to CNNs. One of the mostly lauded achievements of CNNs is their ability to recognize handwritten digits. It is quite hard to tell what makes a handwritten three a 3. But if you let a CNN look at a sufficient number of handwritten 3s, at some point it comes up, by the virtue of back propagation, with a set of features that, when present, uniquely identify a 3. There is a reasonably comprehensive tutorial on tensorflow.org site that shows how to program a neural network to solve this specific task. My goal is not to repeat it. Instead I go over the concepts that make CNNs such a powerful tool.
In this series of posts I show how to develop a CNN that can recognize all 10 digits shown by a hypothetical LCD display. I start with a simple linear regression to show that automatic derivation of features is not specific to CNNs. By adding a degree of freedom, where digits can appear in a larger image, I show that simple linear regression is not sufficient. One possible approach is to use deep neural networks (DNNs), but they too have limits. The final solution is probably the simplest CNN one can build. Despite its simplicity, it is 100% successful in recognizing all ten digits, regardless of their position on the screen.

 . Next, we compute
. Next, we compute  , where
, where  is a 25 by 10 matrix and
is a 25 by 10 matrix and  is a vector of size 10.
is a vector of size 10.![\left[ \begin{array}{ccccccc} 1 & 1 & 1 & \cdots & 1 & 1 & 1 \\ 0 & 0 & 0 & \cdots & 0 & 0 & 1 \\ 1 & 1 & 1 & \cdots & 1 & 1 & 1 \\ & & & \ddots & & & \\ 1 & 1 & 1 & \cdots & 1 & 1 & 1 \\ 1 & 1 & 1 & \cdots & 0 & 0 & 1 \end{array} \right] \times \left[ \begin{array}{cccc} w_{0,0} & w_{0,1} & \cdots & w_{0,9} \\ w_{1,0} & w_{1,1} & \cdots & w_{1,9} \\ w_{2,0} & w_{2,1} & \cdots & w_{2,9} \\ & & \ddots & \\ w_{23,0} & w_{23,1} & \cdots & w_{23,9} \\ w_{24,0} & w_{24,1} & \cdots & w_{24,9} \end{array} \right] + \left[ \begin{array}{c} b_0 \\ b_1 \\ \vdots \\ b_9 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bccccccc%7D+1+%26+1+%26+1+%26+%5Ccdots+%26+1+%26+1+%26+1+%5C%5C+0+%26+0+%26+0+%26+%5Ccdots+%26+0+%26+0+%26+1+%5C%5C+1+%26+1+%26+1+%26+%5Ccdots+%26+1+%26+1+%26+1+%5C%5C+%26+%26+%26+%5Cddots+%26+%26+%26+%5C%5C+1+%26+1+%26+1+%26+%5Ccdots+%26+1+%26+1+%26+1+%5C%5C+1+%26+1+%26+1+%26+%5Ccdots+%26+0+%26+0+%26+1+%5Cend%7Barray%7D+%5Cright%5D+%5Ctimes+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcccc%7D+w_%7B0%2C0%7D+%26+w_%7B0%2C1%7D+%26+%5Ccdots+%26+w_%7B0%2C9%7D+%5C%5C+w_%7B1%2C0%7D+%26+w_%7B1%2C1%7D+%26+%5Ccdots+%26+w_%7B1%2C9%7D+%5C%5C+w_%7B2%2C0%7D+%26+w_%7B2%2C1%7D+%26+%5Ccdots+%26+w_%7B2%2C9%7D+%5C%5C+%26+%26+%5Cddots+%26+%5C%5C+w_%7B23%2C0%7D+%26+w_%7B23%2C1%7D+%26+%5Ccdots+%26+w_%7B23%2C9%7D+%5C%5C+w_%7B24%2C0%7D+%26+w_%7B24%2C1%7D+%26+%5Ccdots+%26+w_%7B24%2C9%7D+%5Cend%7Barray%7D+%5Cright%5D+%2B+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+b_0+%5C%5C+b_1+%5C%5C+%5Cvdots+%5C%5C+b_9+%5Cend%7Barray%7D+%5Cright%5D+&bg=fffdfd&fg=606666&s=0&c=20201002)
 referred to as logits.
referred to as logits.  is proportional to the likelihood that the row represents digit
is proportional to the likelihood that the row represents digit 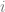 . When training a model, we use gradient descent to nudge the model so that if a row represents, say, a 0, then
. When training a model, we use gradient descent to nudge the model so that if a row represents, say, a 0, then 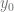 is greater than
is greater than  …
… 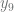 .
.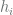 is expressed as
is expressed as
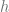 is as close as possible to
is as close as possible to ![[1, 0, 0, 0, 0, 0, 0, 0, 0, 0]](https://s0.wp.com/latex.php?latex=%5B1%2C+0%2C+0%2C+0%2C+0%2C+0%2C+0%2C+0%2C+0%2C+0%5D&bg=fffdfd&fg=606666&s=0&c=20201002) . This requirement is captured with the help of cross entropy function:
. This requirement is captured with the help of cross entropy function:
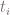 is the true (desired) value, taking either 1 or 0. Let us express the above using Tensorflow:
is the true (desired) value, taking either 1 or 0. Let us express the above using Tensorflow: ,
, 

