In the previous post we were dealing with an idealized setup. Each 5 by 5 digit fills completely a 5 by 5 image. In real world this is a very unusual occurrence. When processing images there is no guarantee that subjects completely fill them. The subject may be rotated, parts of it might be cut off, shadows may obscure it. The same applies to processing sounds. Ambient noises may be present, the sound we are interested in may not start right at the beginning of the recording, and so on. In this post we are going to show how adding a small degree of uncertainty can defeat an approach based on linear regression. We show how deep neural network can deal with this more complex task, at the expense of a much larger model and longer training time.
Adding uncertainty
In order to simulate a real world setup we are going to slightly alter image generation. Previous image size and shape size were both set to 5. This way each shaped filled perfectly the entire image. There was no uncertainty as to where the image is located. Here we increase the image size to be twice the size of the shape. This leads to shape “jitter”, where the shape can be located anywhere in 10 by 10 grid, as shown in Fig 1.

Fig 1. LCD digits randomly located on a 10 x 10 grid.
Simple approach
We start by simply modifying img_size variable and running the same linear regression. Somewhat surprisingly, after 5 steps we hit 73% accuracy. When we complete the remaining steps, we reach 100% accuracy. It seems that this approach worked. However, this is not the case. Our linear regression learned perfectly the 100 examples we had. The mistake of the simple approach is not using any test data. Typically, when training a model, it is recommended that about 80% of data is used as training data, and 20% are used as test data. Fortunately, we can easily rectify this. We generate another 50 examples, and evaluate accuracy for those. The result is 8%, or slightly worse than by a random chance. To see why this is the case, let us look at matrix W. Again, we reshape it as a 10 by 10 square, and normalize it within -1 to 1 value. The result is shown in Fig 2.

Fig 2. Matrix W at the end of training with 100 10×10 images
Now it is obvious that rather than learning how to recognize a given number, linear regression learned the location of each digit. If there is, say, 4 leaning against the left side of the image, it is recognized. However, once it is moved to the location not previously seen, the model lacks the means to recognize it. This is even more obvious if we run the training step with more examples. Rather than maintaining the accuracy, the quality of the solution quickly deteriorates. For example, if we supply 500 rather than 100 examples, the accuracy drops to 54%. Increasing the number of examples to 5,000 drops the accuracy to a dismal 32%. The confusion matrix shows that the only digit that the model learned to recognize is 1.

Fig 3. Confusion matrix for 5,000 examples.
Conclusions
Linear model is sufficient only for the most basic case. Even for a highly regular items, such as LCD digits, the model is not capable of learning to recognize them as soon as we permit a small “jitter” in the location of each digit. The above example also shows how important it is to have training and test data sets. Linear regression gave an impression of correctly learning each digits. Only by testing the model against independent test data we discovered that it learned positions of all 100 digits, not how to recognize them. This is reminiscent of case of a neural network that was trained to recognize between tanks camouflaged among trees and just trees (see Section 7.2. An Example of Technical Failure). It seemed to performed perfectly, until it was realized that photos of camouflaged tanks were taken on cloudy days, while all empty forest photos were taken on sunny days. The network learned how to recognize sunny from cloudy days, and knew nothing about tanks.
In the next installment we are going to increase the accuracy by creating a deep neural network.
Resources
You can download the Jupyter notebook from which code snippets and images were presented above from github linreg-large repository.
 that tells us how confident we are that a given
that tells us how confident we are that a given  is a positive example, we wish to select
is a positive example, we wish to select  that results in
that results in  for all positive examples. By the same token, we would like
for all positive examples. By the same token, we would like 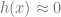 for all negative examples. The difference between the “least positive” and the “least negative” examples is the margin. By maximizing that margin we maximize the chances of yet unseen positive examples being recognized as such. The same holds for yet unseen negative examples. If we deal with linearly separable data, this is equivalent to finding a hyperplane (in case of 2D data, this is just a line) that maximizes the margin between positive and negative examples (see Fig 1)
for all negative examples. The difference between the “least positive” and the “least negative” examples is the margin. By maximizing that margin we maximize the chances of yet unseen positive examples being recognized as such. The same holds for yet unseen negative examples. If we deal with linearly separable data, this is equivalent to finding a hyperplane (in case of 2D data, this is just a line) that maximizes the margin between positive and negative examples (see Fig 1)
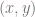 ,
,  the point is considered a part of a positive class. Otherwise, it falls into the negative class. As randomly generated points would not likely to have a margin separating positive from negative examples, we add the margin by pushing positive points
the point is considered a part of a positive class. Otherwise, it falls into the negative class. As randomly generated points would not likely to have a margin separating positive from negative examples, we add the margin by pushing positive points  left and up. Negative examples are pushed right and down by
left and up. Negative examples are pushed right and down by  .
. has class 0, and logits
has class 0, and logits 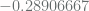 , indicating that it barely makes class 0. On the other hand
, indicating that it barely makes class 0. On the other hand  , which also belongs to class 0, has logits
, which also belongs to class 0, has logits  .
.
