Introduction
In lecture 12 Andrew Ng introduces support vector machines (SVMs). As Andrew Ng shows the intuition for what SVMs are can be gleaned from logistic regression. If we have a function 



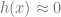

Fig 1. Positive (red) and negative (blue) examples with the separating hyperplane (line) and its margins.
Without going into formalities, which are much better explained in Andrew Ng’s lecture notes, the task of finding such a hyperplane can be cast as task for finding support vectors for it. These can be efficiently found using gradient descent methods, with a slightly modified definition of the loss function.
SVM with Tensorflow
Tensorflow added, in version 1.0, tf.contrib.learn.SVM. It implements the Estimator interface. As with other estimators the approach is to create an estimator, fit known examples, while periodically evaluating the fitness of the estimator on the validation set. Once the evaluator is trained, it may be exported. From then on, for any new data, you use prediction to classify it.
Preparing Data
The first step is to prepare data, similar to the one shown in Fig 1. In real application this data would be collected from external sources, rather than generated. We generate a set of 1,000 random points. Each point is assigned a class. If for the given point 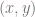



min_y = min_x = -5 max_y = max_x = 5 x_coords = np.random.uniform(min_x, max_x, (500, 1)) y_coords = np.random.uniform(min_y, max_y, (500, 1)) clazz = np.greater(y_coords, x_coords).astype(int) delta = 0.5 / np.sqrt(2.0) x_coords = x_coords + ((0 - clazz) * delta) + ((1 - clazz) * delta) y_coords = y_coords + (clazz * delta) + ((clazz - 1) * delta)
Preparing Input Function
For a given data we create an input function. The role of this function is to feed data and labels to the estimator. The data, for SVM, consist of a dictionary holding feature IDs, and features themselves. The labels tell the estimator the class to which each row of features belongs. In more complex setup the input function can return batches of data read from a disk or over a network. It can indicate the end of data by raising StopIteration or OutOfRangeError exception. For us the function trivially returns all 1,000 points with their labels.
def input_fn():
return {
'example_id': tf.constant(
map(lambda x: str(x + 1), np.arange(len(x_coords)))),
'x': tf.constant(np.reshape(x_coords, [x_coords.shape[0], 1])),
'y': tf.constant(np.reshape(y_coords, [y_coords.shape[0], 1])),
}, tf.constant(clazz)
Training SVM
Once the input function is set up, we create a new SVM estimator. In the constructor we tell it the names of the features, which for us are real valued columns. We also indicate which column holds the IDs for each row of features. Having done that we ask SVM to fit input data for a fixed number of steps. Since our data is trivially separable, we limit the number of steps to just 30. Next, we run one more step to estimate the quality of fit. For a trivial example the SVM achieves a perfect accuracy. In real application, the quality should be estimated on a data separate from the one used to train SVM.
feature1 = tf.contrib.layers.real_valued_column('x')
feature2 = tf.contrib.layers.real_valued_column('y')
svm_classifier = tf.contrib.learn.SVM(
feature_columns=[feature1, feature2],
example_id_column='example_id')
svm_classifier.fit(input_fn=input_fn, steps=30)
metrics = svm_classifier.evaluate(input_fn=input_fn, steps=1)
print "Loss", metrics['loss'], "\nAccuracy", metrics['accuracy']
Loss 0.00118758
Accuracy 1.0
Predicting Classes for New Data
Once SVM has been trained, it can be used to predict the class of a new, previously unseen data. To simulate this step we again generate random points and feed them to the trained SVM. SVM not only returns the class for each point, but gives us the logits value. The latter can be used to estimate the confidence in the class assigned to the point by the SVM. For example, a point 
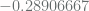


x_predict = np.random.uniform(min_x, max_x, (20, 1))
y_predict = np.random.uniform(min_y, max_y, (20, 1))
def predict_fn():
return {
'x': tf.constant(x_predict),
'y': tf.constant(y_predict),
}
pred = list(svm_classifier.predict(input_fn=predict_fn))
predicted_class = map(lambda x: x['classes'], pred)
annotations = map(lambda x: '%.2f' % x['logits'][0], pred)
The results of classification of random points, together with the logits values for each point are shown in Fig 2.

Fig 2. SVM prediction for a set of random points.
Resources
You can download the Jupyter notebook with the above code from a github svm repository.
